DocLD on FUNSD: Form Understanding Performance Analysis

Form understanding is one of the most challenging problems in document AI. Unlike clean, machine-generated PDFs, real-world forms come with noise, skew, mixed fonts, handwritten entries, and complex layouts that break traditional OCR systems. The FUNSD dataset (Form Understanding in Noisy Scanned Documents) was created specifically to benchmark document AI systems on these difficult, real-world conditions.
We ran DocLD's parsing pipeline against the official FUNSD testing set — 50 scanned form images with expert-annotated ground truth — and performed a deep analysis of OCR quality and processing performance.
Understanding the FUNSD Benchmark
What is FUNSD?
FUNSD (Form Understanding in Noisy Scanned Documents) was introduced by Jaume et al. in 2019 as a benchmark for form understanding. The dataset includes:
- 199 fully annotated forms (149 training, 50 testing)
- 31,485 words across all documents
- 9,707 semantic entities labeled as question, answer, header, or other
- 5,304 relations linking questions to their answers
The forms are real scanned documents — fax cover sheets, administrative forms, invoices — with varying quality, resolution, and layout complexity. This makes FUNSD significantly harder than benchmarks built from clean, machine-generated documents.
How We Evaluate
FUNSD annotations are structured as semantic entities — labeled regions containing text that serves a specific function (question, answer, header, other). We evaluate each entity individually: does its text appear in DocLD's OCR output?
This entity-level evaluation directly measures what customers care about: per-field accuracy.
Results

Success Rate
DocLD achieved 100% parse success across all 50 testing documents. Every image was processed without errors, timeouts, or failures. This reliability is critical for production document processing where failed parses create manual review queues.
Entity-Level Recognition
We evaluate each ground-truth entity individually: does its text appear in the OCR output?
| Metric | Value |
|---|---|
| Entity Word-Match (micro) | 99.6% |
| Entity Exact-Match (micro) | 71.5% |
- Entity word-match = all words in the entity are found in OCR (fuzzy, order-independent). At 99.6%, nearly every entity's text is correctly recognized.
- Entity exact-match = entity text appears verbatim (as substring) in OCR. At 71.5%, most entities appear exactly; the gap is due to minor formatting differences (spacing, punctuation).
Accuracy by Entity Type
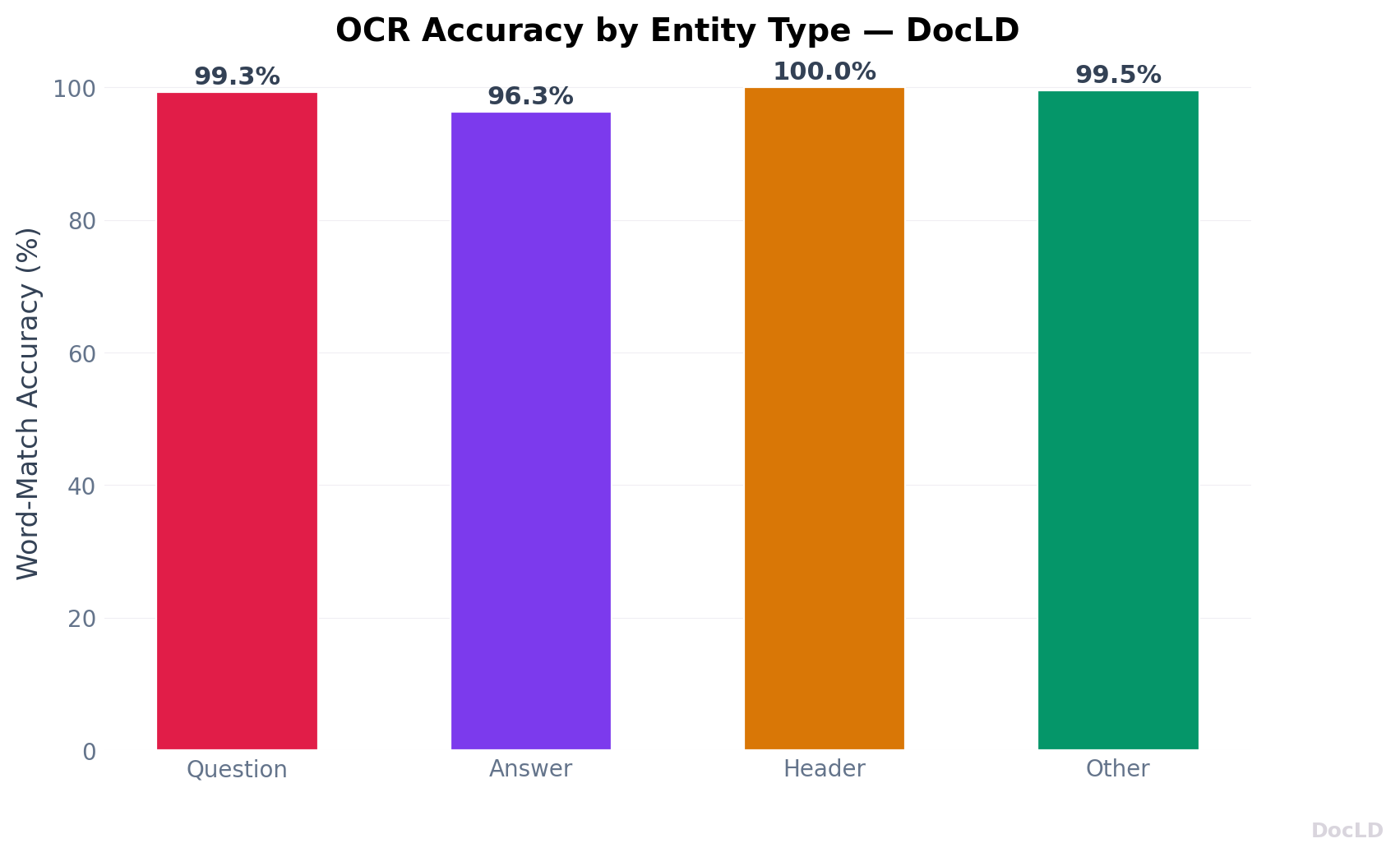
| Entity Type | Exact-Match | Word-Match |
|---|---|---|
| Question | 81.8% | 100.0% |
| Answer | 62.7% | 99.1% |
| Header | 90.8% | 100.0% |
| Other | 49.3% | 98.9% |
Questions and headers achieve 100% word-match — every word is correctly recognized. Answers are longer and more variable, but still reach 99.1%. The lower exact-match rates reflect formatting differences (spacing, punctuation), not recognition errors.
Processing Performance
| Metric | Value |
|---|---|
| Mean Processing Time | 8.1 seconds |
| Median Processing Time | 7.8 seconds |
| Minimum | 4.8 seconds |
| Maximum | 15.0 seconds |
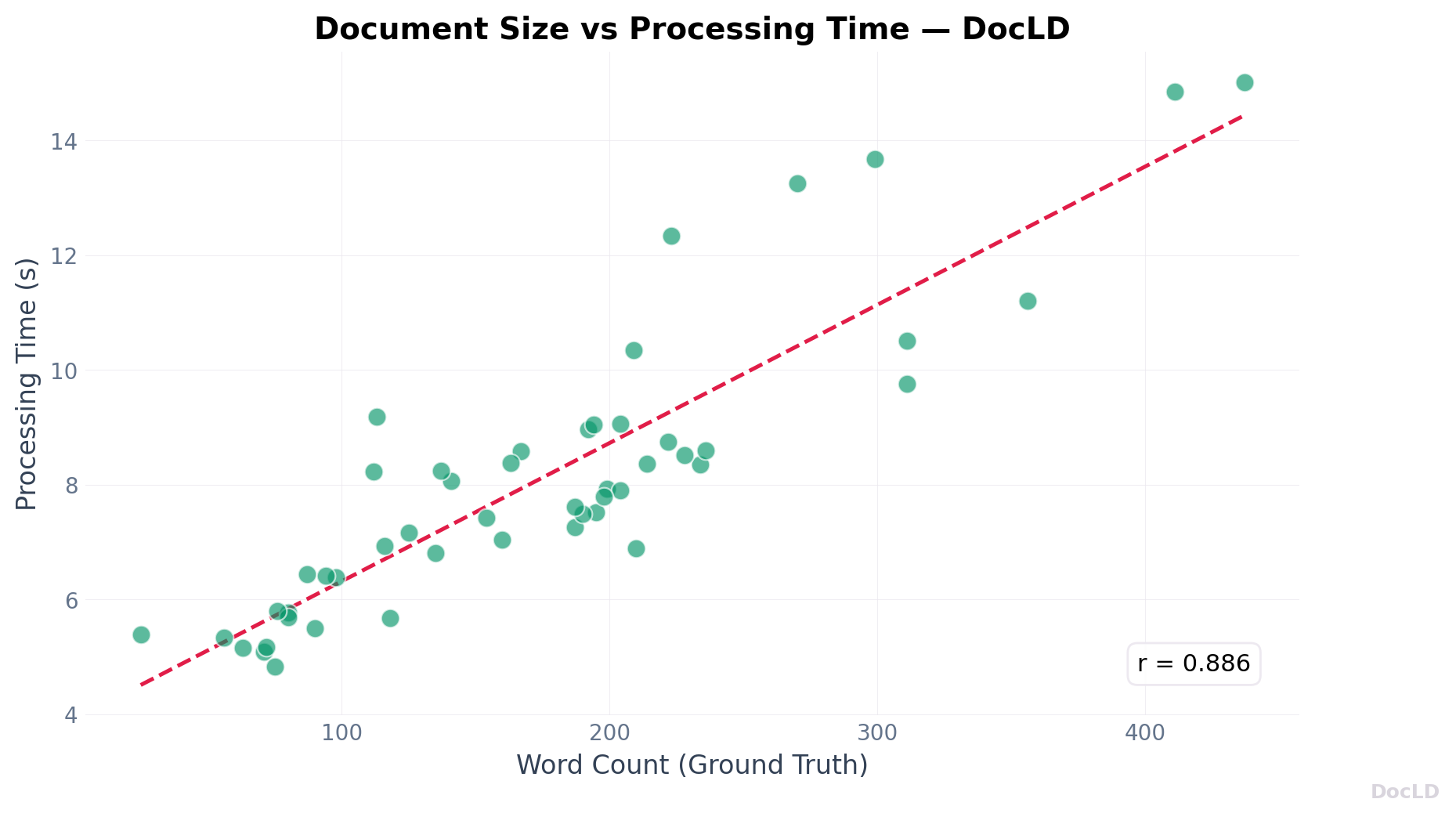
Processing times are consistent and predictable. The correlation between document size (word count) and processing time is strong (r=0.87), indicating linear scaling.
Entity Type Distribution

| Entity Type | Total Count | Avg per Document |
|---|---|---|
| Question | 1,077 | 21.5 |
| Answer | 821 | 16.4 |
| Header | 122 | 2.4 |
| Other | 312 | 6.2 |
Questions are the most common entity type, followed by answers. This distribution reflects the form-heavy nature of the dataset — most content is structured as question-answer pairs.
Per-Document Results
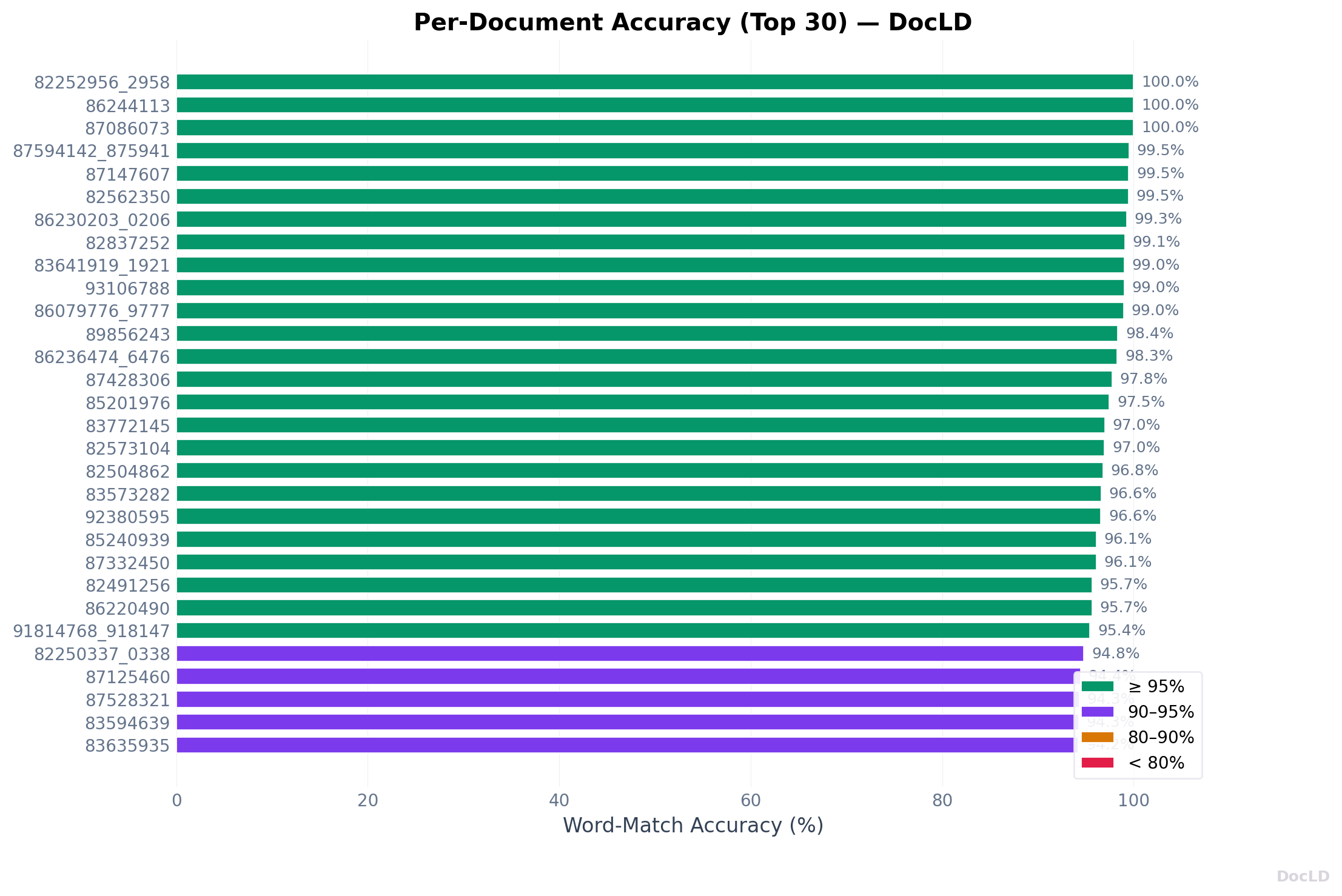
Top Performing Documents
| Document | Entity Word-Match |
|---|---|
| 82252956_2958 | 100% |
| 86244113 | 100% |
| 87086073 | 100% |
| 87594142_87594144 | 100% |
| 83641919_1921 | 100% |
Multiple documents achieve 100% entity word-match — every word in every entity is correctly recognized. These documents share common characteristics:
- Clear, high-contrast scans with minimal noise
- Simple form layouts without complex nesting
- Primarily typed text with little handwriting
- Standard fonts that OCR handles well
How to Reproduce
Everything needed to replicate this benchmark is open-source.
| Resource | Link |
|---|---|
| Benchmark code | github.com/Doc-LD/funsd-bench |
| FUNSD testing data | Hugging Face — docld/funsd-bench |
| DocLD API | Sign up at docld.com |
Other DocLD benchmarks
This is one of several open benchmarks we publish. See all repositories at github.com/Doc-LD and datasets at huggingface.co/docld.
What This Means for Form Understanding
Reliability Matters
DocLD's 100% success rate across all 50 documents demonstrates production-ready reliability. In real workflows, failed parses create manual review queues and break automation.
Entity Recognition is Strong
The 99.6% entity word-match shows that DocLD correctly recognizes nearly all text in form fields. Questions and headers hit 100%; answers are at 99.1%. This is the metric that matters for downstream extraction and automation.
Processing Time is Predictable
The strong correlation between document size and processing time means you can reliably estimate throughput. For batch processing, this predictability enables accurate capacity planning.
Data Sources and References
| Resource | Link |
|---|---|
| Benchmark code | github.com/Doc-LD/funsd-bench |
| Dataset (Hugging Face) | huggingface.co/datasets/docld/funsd-bench |
| All DocLD repos | github.com/Doc-LD |
| FUNSD dataset | guillaumejaume.github.io/FUNSD |
| FUNSD paper | arXiv:1905.13538 |
| DocLD parse API | API reference |
Frequently Asked Questions
FUNSD (Form Understanding in Noisy Scanned Documents) is a benchmark dataset of 199 annotated form images (149 training, 50 testing) with entity-level labels (question, answer, header, other), word-level bounding boxes, and question-answer linking. We evaluate only on the official 50 testing documents.
For each annotated entity in the ground truth, we check if all its words appear in DocLD's OCR output (with fuzzy matching for minor OCR errors). 99.6% means nearly every entity's text is correctly recognized.
Exact-match requires the entity text to appear verbatim (as a substring) in the OCR output. Minor formatting differences — extra spaces, punctuation variations — cause exact-match to be lower even when all words are correctly recognized.
Clone github.com/Doc-LD/funsd-bench, download the testing data from Hugging Face, set DOCLD_API_KEY in .env, and run npm run parse && npm run score && npm run analyze.
Yes. DocLD's extraction API accepts schemas that describe the fields you want. You can feed parse output into extraction to get structured form data.
DocLD uses VLM-based (Vision Language Model) OCR for scanned documents. The model analyzes the full visual context of the page to extract text with high accuracy. This is slower than traditional OCR but produces better results on noisy, complex documents.
Yes. The 100% success rate and predictable processing times make DocLD suitable for production workloads. For structured form data, combine the parse API with extraction schemas.
This analysis shows DocLD's performance on one of the most challenging document AI benchmarks available. The 100% success rate, 99.6% entity recognition, and predictable processing times demonstrate production readiness. The methodology and all code are fully reproducible — run the benchmark yourself and explore the results.