Turn technical documents into structured data.
DocLD helps engineering and product teams process API docs, specs, release notes, and compliance documents where precision matters. Parse technical PDFs, Office files, and scans with one API — layout-aware extraction, OCR for legacy docs, and citation-ready chunks for RAG and knowledge bases.
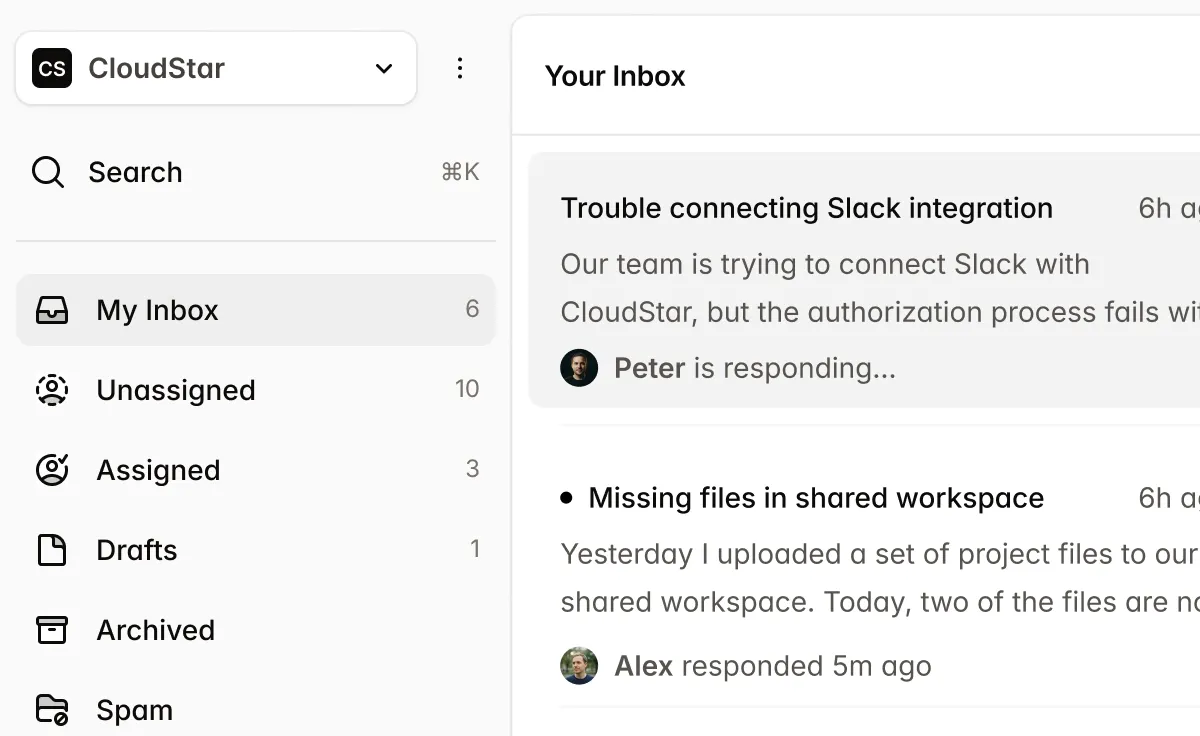
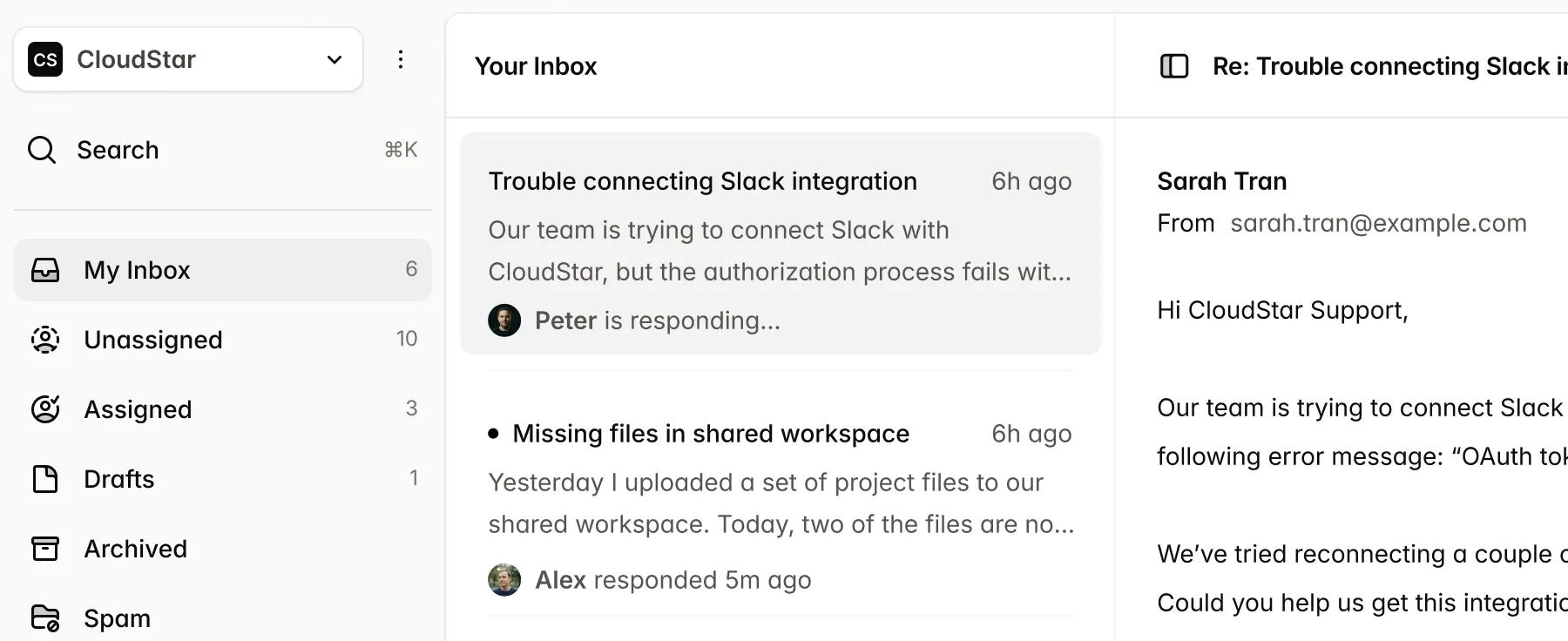
Technical docs and API specs
API docs, OpenAPI/Swagger, and specs mix text, code blocks, and tables.
API documentation, OpenAPI/Swagger specs, and technical specs combine prose, code blocks, and tables where critical data lives. DocLD parses PDFs and documents with layout-aware extraction so you get clean text and table structure — including from embedded schemas and parameter tables — in a single API call.
Parse returns chunks with page and bounding-box context, so you can build RAG and ingestion pipelines that cite back to the exact section or endpoint.
SDK and developer docs
Multi-format docs: PDF, Markdown, HTML, and versioned content.
SDK guides, developer docs, and runbooks often live in PDF, Markdown, HTML, and Office formats with varying structure. DocLD supports these with the same Parse API so you get clean text and structure for ingestion, RAG, and internal knowledge bases without format-specific integrations.
Use the same pipeline for PDFs, images, and Office documents; switch formats without changing your code.
Release notes and changelogs
Versioned release notes and changelogs with structured content.
Release notes and changelogs combine version numbers, dates, and feature descriptions in dense or list form. DocLD parses these with layout-aware extraction so you get structured content for search, summarization, and integration into internal tools or customer-facing dashboards.
Use the Extract API with schemas to pull version, date, and change-type fields with citations back to the source.
Compliance and audit
SOC2, security questionnaires, and audit docs need traceable outputs.
SOC2 documentation, security questionnaires, and audit packs require linking every answer back to its source. DocLD Parse returns chunks with page ranges and optional bounding boxes; Extract can pull structured fields with citations. Build RAG and agent flows that show where each response came from for audit trails and vendor reviews.
Run parsing and extraction via API in your own environment, with configurable presets and webhooks for batch intake.
Long manuals and batch
Technical manuals, specs, and large doc sets.
Technical manuals, architecture specs, and documentation sets can run to hundreds of pages. DocLD supports files up to 100MB with semantic, fixed-size, or page-based chunking so you can tune for RAG quality and context windows.
Use the async Parse endpoint and webhooks for large documents and batch jobs — no need to block on synchronous responses when processing doc migrations or bulk ingestion.
How teams use DocLD in technology
| Use case | Description |
|---|---|
| Technical knowledge retrieval | Turn API docs, specs, and runbooks into a searchable knowledge base with citation-backed answers for support and engineering. |
| API and spec ingestion | Parse OpenAPI/Swagger docs, technical specs, and schema PDFs for automated ingestion and internal tooling. |
| Release note summarization | Extract version, date, and change content from release notes and changelogs for dashboards and customer communications. |
| Compliance documentation | Ingest SOC2, security questionnaires, and audit docs with citation-ready output for vendor reviews and audits. |
| Developer onboarding | Build searchable internal docs and runbooks from PDFs and Office files so new hires find answers faster. |
| Contract and SLA extraction | Parse vendor contracts, SLAs, and terms; structure key dates, obligations, and limits for procurement and legal. |
Technology: Questions & Answers
Ready to process technical documents?
Get started with the Parse API in minutes. Sign up for free or read the API reference for request formats, webhooks, and presets.