Turn financial documents into structured data.
DocLD helps hedge funds, trading desks, and fintech teams process high-volume, multi-format documents where precision matters. Parse research reports, filings, spreadsheets, and statements with one API — layout-aware extraction, OCR for scans, and citation-ready chunks for RAG and compliance.
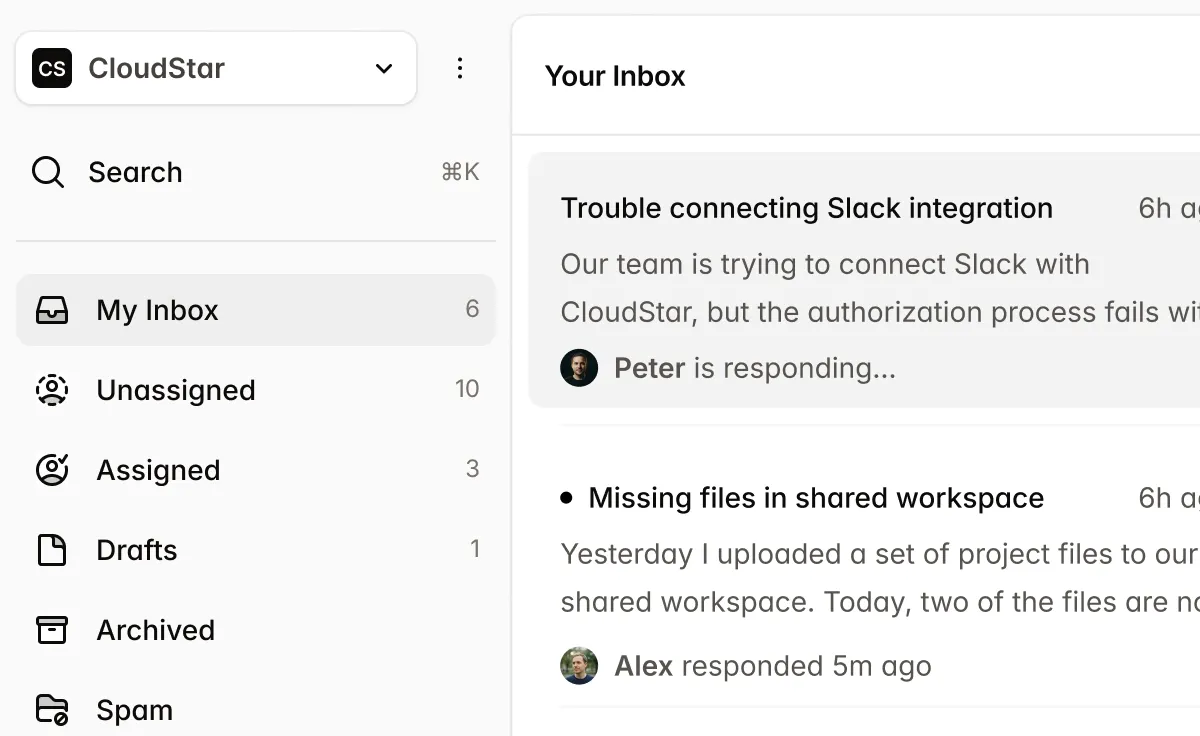
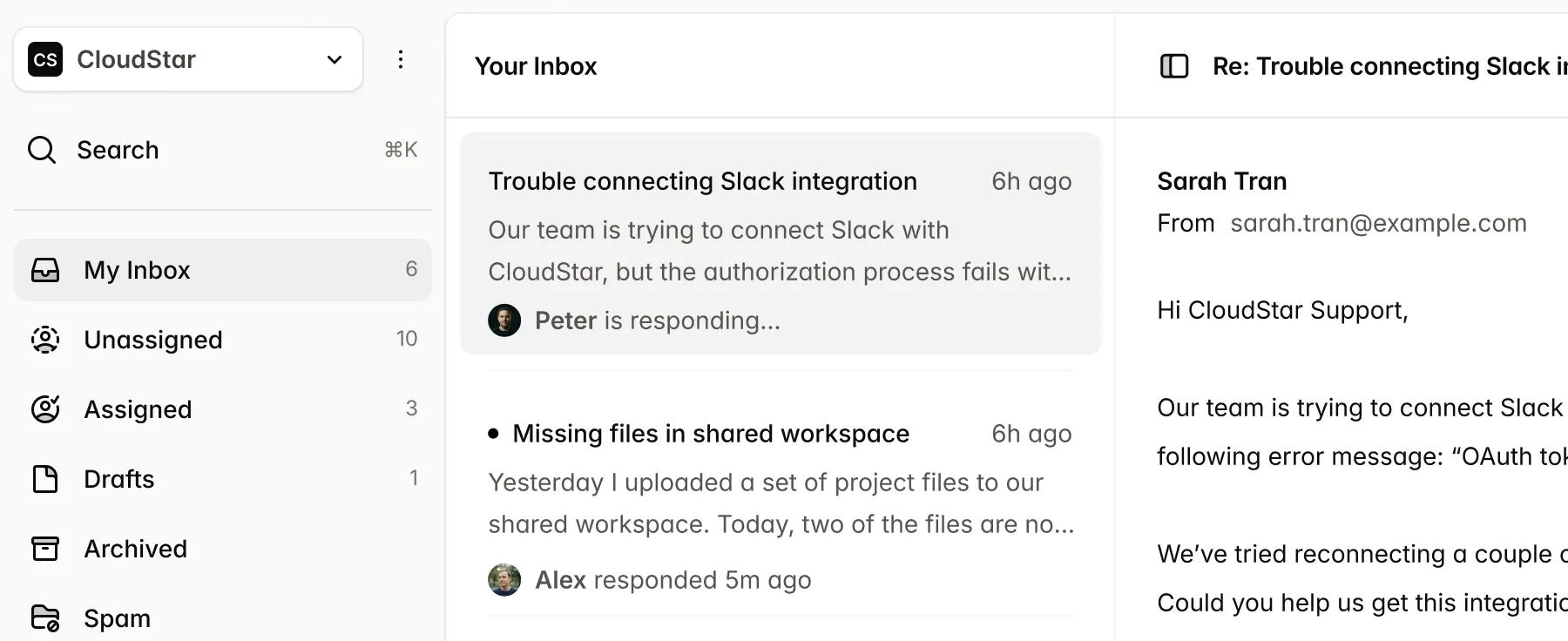
Multimodal reports and filings
Research PDFs and filings mix dense text with charts, tables, and footnotes.
Financial research and regulatory filings combine text, charts, tables, and footnotes where critical data often lives only inside figures or fine print. DocLD parses PDFs and images with layout-aware extraction and optional agentic OCR, so you get text and table structure — including from embedded charts and multi-level tables — in a single API call.
Parse returns chunks with page and bounding-box context, so you can build RAG and extraction pipelines that cite back to the exact cell or disclosure.
Complex spreadsheets and models
Financial models and analyses use clustered tables, multiple tabs, and linked sheets.
Financial models, broker statements, and analyses often use multi-tab workbooks, merged cells, and linked sheets. DocLD supports CSV, XLSX, XLS, and related formats with structured extraction so you get clean table data — not just raw text — for modeling and quantitative workflows.
Use the same Parse API for spreadsheets as for PDFs and images; switch formats without changing your pipeline.
Compliance and auditability
Financial workflows demand enterprise security and traceable outputs.
Finance teams need to link every metric and decision back to its source. DocLD Parse returns chunks with page ranges and optional bounding boxes; Extract can pull structured fields with citations. Build RAG and agent flows that show where each answer came from, so your outputs stay traceable and audit-ready.
Run parsing and extraction in your own environment via API, with configurable presets and webhooks for batch jobs.
Long, dense documents
Research reports and investor materials span hundreds of pages.
Research reports, prospectuses, and investor materials can run to hundreds of pages, each packed with data that must be preserved and retrievable. DocLD supports files up to 100MB with semantic, fixed-size, or page-based chunking so you can tune for RAG quality and context windows.
Use the async Parse endpoint and webhooks for large documents and batch jobs — no need to block on synchronous responses.
Scans and statements
Brokerage statements, policy documents, and handwritten forms.
Brokerage statements, insurance documents, and signed forms often arrive as scans or mixed handwriting and print. DocLD uses VLM-based OCR with 50+ languages, auto-detection, and table extraction. Enable agentic mode for better accuracy on complex tables and forms.
Push parsed holdings and transaction data into risk tools, advisor systems, or your own databases via a single ingestion pipeline.
How teams use DocLD in finance
| Use case | Description |
|---|---|
| Market research & data intake | Parse research reports, filings, news articles, and slide decks for faster analysis and modeling. |
| Risk and holdings assessment | Extract 401(k) and brokerage holdings from statements and push structured data into risk tools. |
| Financial knowledge retrieval | Turn unstructured research into a searchable knowledge base with citation-backed answers. |
| Chart and table extraction | Convert line graphs, visual charts, and multi-level tables into clean data for quantitative workflows. |
| Advisor book-of-business | Parse insurance statements, policy performance, and account values to update advisor databases automatically. |
| Financial contract extraction | Parse credit agreements, term sheets, and loan docs; structure covenants, rates, and collateral terms for decisioning. |
Finance: Questions & Answers
Ready to process financial documents?
Get started with the Parse API in minutes. Sign up for free or read the API reference for request formats, webhooks, and presets.